> For the complete documentation index, see [llms.txt](https://zhenghe.gitbook.io/open-courses/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://zhenghe.gitbook.io/open-courses/stanford-cs107/di-qi-ba-ke-yun-hang-shi-nei-cun-jie-gou.md).
# 运行时内存结构
#### 引入
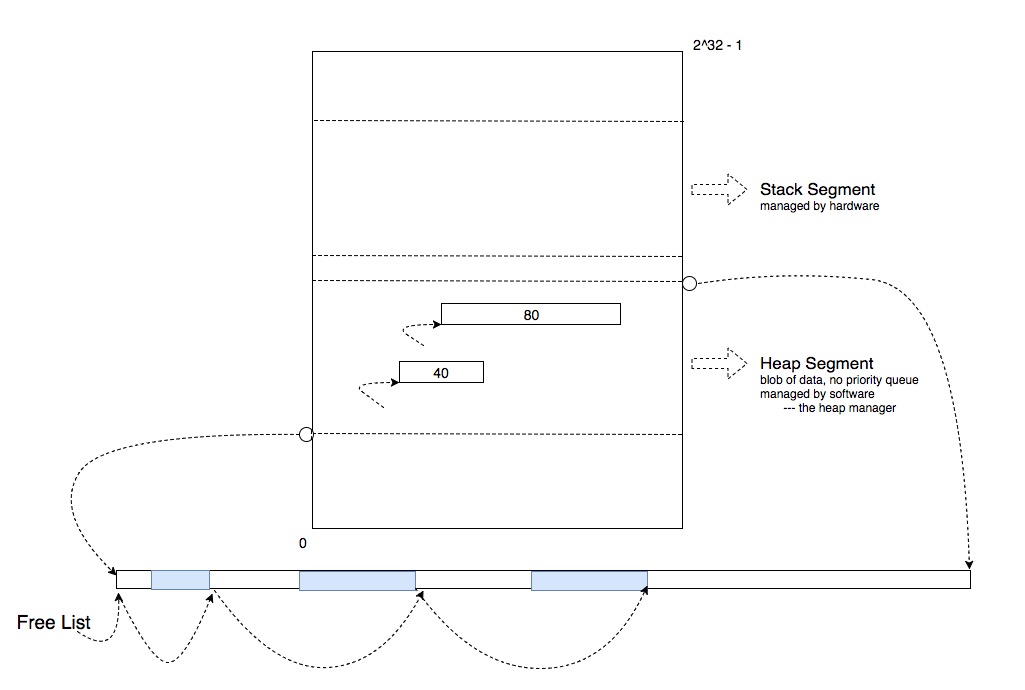
在指针长度为 4 个字节的系统中,内存地址最多有 2^32 个,我们可以将内存看作一个大的长方形区域,左下角是地址 0 ,右上角是地址 2^32 - 1。运行时内存结构最重要的三个部分分别是 Stack Segment 、Heap Segment 和 Code Segment。Stack 用于追踪当前运行时的足迹,局部变量;Heap 是一个空间池子,用于支持动态内存空间的分配;Code 用于存储 C 程序编译后的汇编程序。
#### Heap Segment
在数值较小的地址区域上,有一块区域被称为 Heap Segment,这里存着当前运行过程中动态分配的内存空间。这里的 Heap 与数据结构中的 Priority Queue 并无任何关系,在这里它仅仅指的是一个数据块,而这个数据块的分配与回收,是由软件直接控制的,该软件被称为 Heap Manager。当 malloc 被调用时,Heap Manager 会在 Heap Segment 中找到一块符合要求的内存空间,将它分配出去并记录,然后把该空间的起始地址返回给调用者;当 realloc 被调用时,Heap Manager 会首先检查该传入的地址是否被分配了空间,如果没有则调用 malloc,如果有则检查原先分配的空间是否满足 realloc 参数中指定的大小,如果满足,就直接返回;如果不满足,则首先检查原先分配的空间之后是否有足够的空闲空间满足,如果满足则直接分配所需的剩余空间,如果不满足则从 Heap Segment 中重新分配一块符合要求的空间,并将原分配空间中的数据拷贝到新的空间中,同时返回新空间的地址。
Heap Manager 并没有特殊能力,它将 HeapSegment 中的剩余可用空间像串糖葫芦一样把它们串起来,称为 freeList,然后利用 freeList 来寻找满足需求的内存空间。
**走近 Heap Manager**
```c
int *arr = malloc(40 * sizeof(int));
```
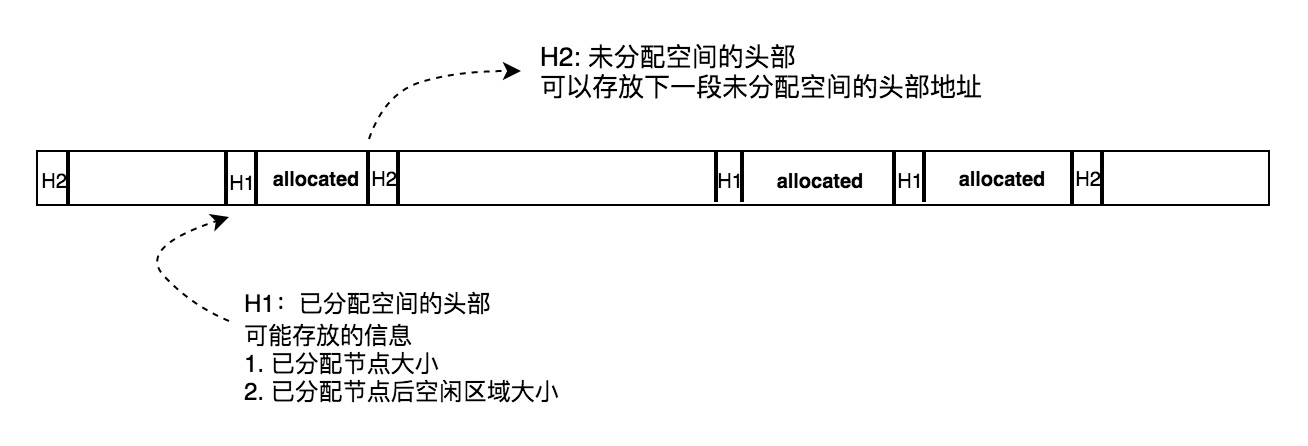
如以上代码所示,当你调用 malloc 的时候,Heap Manager 在 Heap 内部并不是只分配对应大小的空间 (160 字节),而是会分配比要求的多一些空间,存储对 Heap Manager 有用的头部信息,如分配空间的大小信息:
**敏感的小明**
小明是个刚学习 C 并对内存资源十分敏感的程序员,他写出了如下代码:
```c
int *arr = malloc(100*sizeof(int));
// do anything he want with the arr
free(arr + 60);
```
问题在于,Heap Manager 有可能会将对它有用的信息存储在已分配内存块的头部,而 arr + 60 所指向的 Heap 地址处并没有相应的头部信息,但如果 Heap Manager 没有做错误检查,它可能会误将 arr + 60 前的一段信息解读为头部信息,因此造成程序崩溃。
小明有时候也会写出这样的代码:
```c
int array[100];
// do anything he want with the array
free(array);
```
如果 free 没有做任何错误检查 (为了性能),这段在 Stack 中分配的内存将被交给 Heap Manager,接下来发生的事情便无法预料。
**Heap Manager 可能会如何利用头部信息?**
Heap Manager 可能会利用已分配内存节点的头部储存当前分配空间大小信息,以及已分配空间后的空闲空间大小信息。前者可以让 Heap Manager 追踪已经分配的空间,后者可以帮助 Heap Manager 确认在 realloc 的时候,是否可以原地分配。
Heap Manager 不仅会利用已分配内存节点的头部存储信息,还会利用未分配内存节点的头部存储信息。Heap Manager 要解决的核心问题是如何在 Heap 中寻找到一块符合要求的空间分配满足当前分配请求,同时分配该空间后,剩余空间能最大限度满足未来的分配请求。要做到这点,首先得做到快速检索所有空闲空间。其中一种做法就是在 Heap 中的每段空闲内存头部保存下一段空闲空间的地址,以此抽象出一张链表,利用链表线性检索剩余空闲空间。由于 Heap 中通常有很多块空闲内存可以满足请求,因此以该链表为基础,Heap Manager 可以实施不同的分配策略来决定将具体哪块空闲内存分配出去,以期达到最优性能。
一些书上常提到的分配策略:
1. best fit
2. worst fit
3. first fit
4. continuous searching
**按索取空间大小划分的分配策略**
有一种类型的 Heap Manager 会把整个 Heap 划分成多个区域,每个区域只用于满足特定范围内的分配需求。如下图所示:
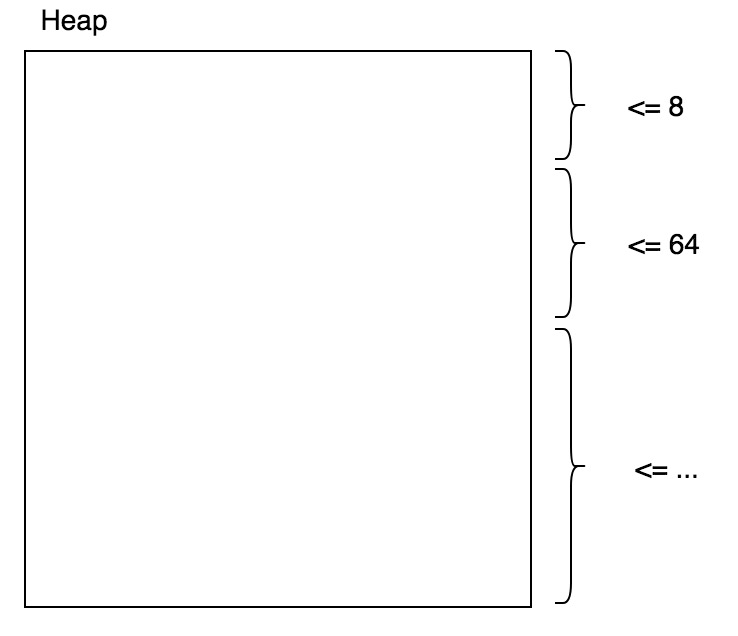
图中顶部区域只负责小于 8 字节的分配需求,且每次分配都取出 8 字节的空间,中部区域只负责大于 8 字节小于 64 字节的空间,且每次分配都取出 64 字节的空间,依次类推。
不同的平台上的 Heap Manager 会有不同的空间分配策略,把分配信息记录在不同的地方,而这些对 C 程序员应该是透明的,C 程序员不能够依赖 Heap Manager 的实现细节来完成变成,也不能够违反抽象时的契约,以非契约规定的方式使用 Heap Manager,否则就可能造成无法预料的后果。
**Compact Heap**
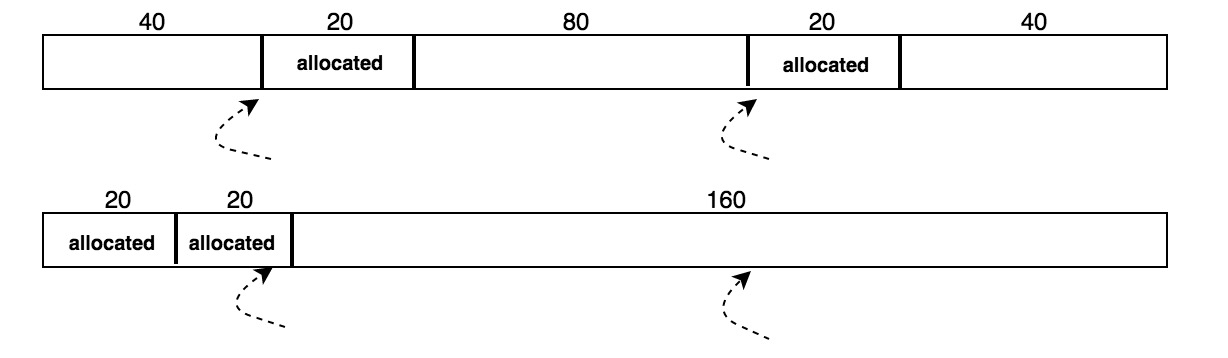
当 Heap 被频繁分配回收以后很可能出现碎片化现象,这种现象可能导致新来的较大的空间分配请求无法得到满足,如下图所示:假设有一个 200 字节的 Heap,已经分配了 40 字节空间,还剩 160 字节,但碎片化使它无法满足一个 120 字节的分配请求,如果能将已分配空间聚集到一起,就能把碎片化的未分配空间合并,满足未来的大空间分配需求。然而,由于 Heap Manager 的用户并不知道这一切,继续使用原来的指针必然会导致错误的信息读写。
Mac OS (7 series) 的做法是在分配空间时,并不把直接内存地址交给用户,而是将指向直接地址的间接地址交给用户,用户使用间接地址时通过两次解指针得到真正的内存地址。这样的好处是系统可以利用守护进程来整理碎片空间,前提是用户在使用之前需要告诉系统停止整理特定的内存区域,也泄露了该层抽象。
#### Stack Segment
在数值较大的地址区域上,有一块区域被称为 Stack Segment,这里存着当前运行环境的函数栈。当 main 函数执行时,它的局部变量被压入栈中,构成该函数的运行环境,当 main 函数调用 A 函数时,main 函数执行的当前地址,即 A 函数的返回地址,以及 A 函数的局部变量被压入栈中,如果 A 函数还有对其它函数的调用则以此类推……直到最后一个函数执行完毕后,它读取上一个函数执行停止处的地址,将当前函数的运行环境从栈中弹出后,继续执行上一个函数……直到回到 main 函数中并将 main 函数执行完毕。运行过程中内存的运行环境都保存在 Stack Segment 中,它由硬件直接控制。
**走近 Stack**
```c
void A() {
int a;
short b[4];
double c;
B();
C();
}
void B() {
int x;
char *y;
char *z[2];
C();
}
void C() {
double m[3],
int n;
// ...
}
```
**Activation Record (or Stack Frame)**
考虑以上代码片段,函数 A 调用函数 B 和函数 C,函数 B 调用函数 C,在执行的过程中,每个函数有自己的 Activation Record, 简称 AR (也称 Stack Frame),在 AR 中从高地址处往低地址处顺序存储着局部变量,如下图所示:
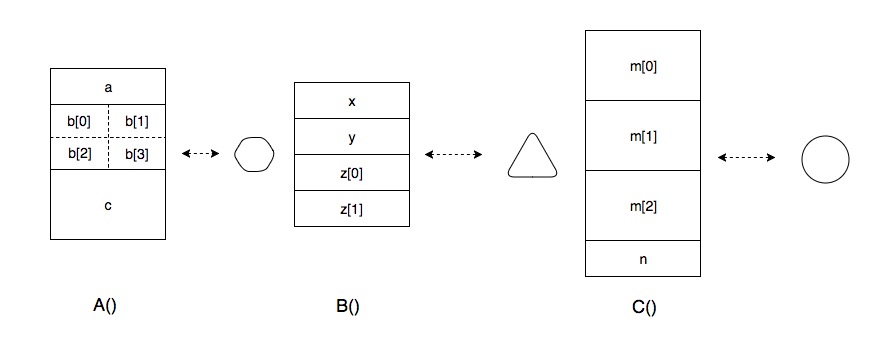将 A、B、C 的 AR 分别抽象成一个正六边形、正三角形和圆形。当 A 执行时,A 函数的 AR,即它的所有局部变量会被放入 Stack 中,此时有一个指针指向该 AR,它叫做 Stack Pointer,下文简称 SP。SP 总是指向当前的 AR,由此,计算机能够利用 AR 地址信息、局部变量相对于 AR 地址,即最后一个局部变量地址,的 offset 来对局部变量寻址。
假设 A 函数在程序中间某处开始执行,从 A 开始执行到 A 执行完成,Stack 与 SP 的关系如下图所示:
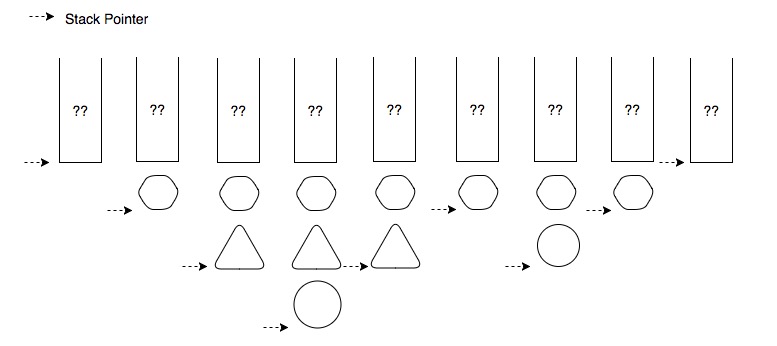
一图胜千言,为什么这个内存结构被称为 Stack 也就一目了然了。
#### 进入 Code Segment 之前 --- 逻辑计算单元(ALU)、寄存器 (Registers) 和内存 (Memory)
如下图所示,在内存与逻辑计算单元之间,有一小块特殊的内存,叫做寄存器。通常,它与逻辑计算单元以及内存直接相连,在物理上就保证了存取的速度。且由于寄存器单元的数量远远小于内存单元的数量,因此寄存器寻址速度也要远远快于内存寻址,同时简化逻辑计算单元内部所需支持的功能。
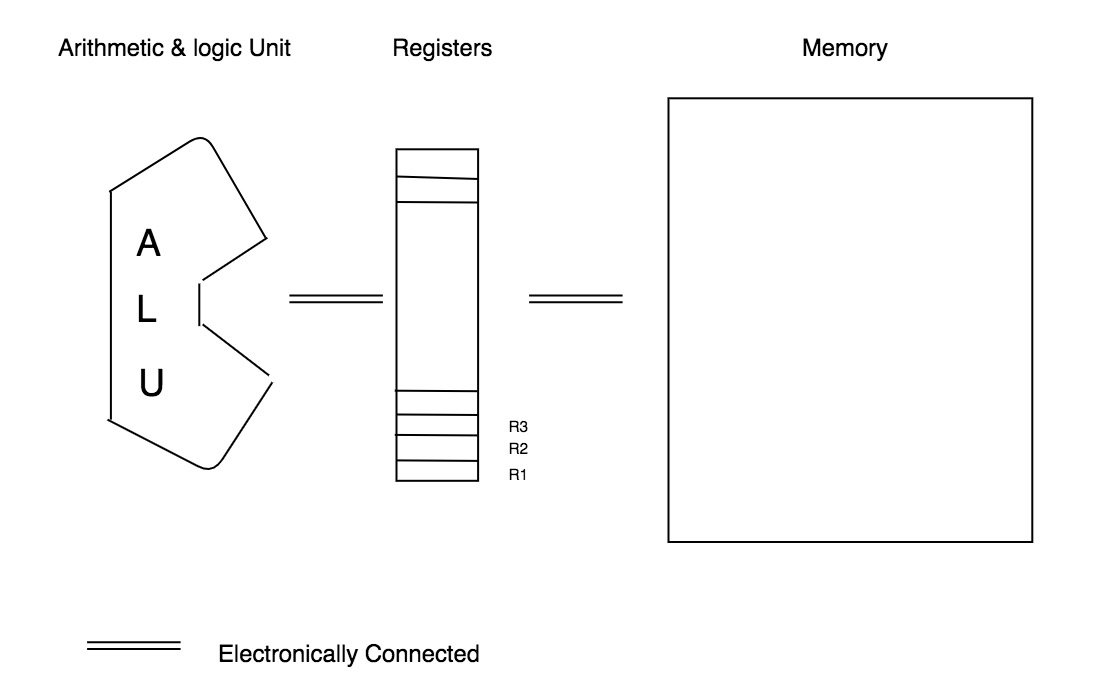
通常一个计算任务可以分拆到极小的子任务,每个任务的基本流程通常是:
1. 从内存中把所需数据读入寄存器
2. 利用逻辑计算单元对寄存器中的数据进行计算,如加、减、乘、位移等等,将结果存回寄存器
3. 将最终结果放回内存中
**参考**
* [Stanford CS107: lecture 7](https://www.youtube.com/watch?v=Yr1YnOVG-4g\&t=124s)
* [Stanford CS107: lecture 8](https://www.youtube.com/watch?v=1nYDflSL0Mg\&list=PL9D558D49CA734A02\&index=8)
* [Github: ZhengHe-MD - lecture codes](https://github.com/ZhengHe-MD/cs107-lecture-codes)