> For the complete documentation index, see [llms.txt](https://zhenghe.gitbook.io/open-courses/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://zhenghe.gitbook.io/open-courses/stanford-cs107/di-si-wu-ke-fan-xing-han-shu.md).
# 泛型函数
#### 从 “指鹿为马” 到泛型函数 (Generic Function)
泛型函数指的是一类对所有类型都适用的函数,使得程序员在使用强类型语言时,不需要为每种类型都写一个相同功能的函数,这也是 DRY (Don't Repeat Yourself) 的一种体现。
通过前两课,我们获得了“指鹿为马”的技能 — 通过强制转换告诉编译器,一个指向 A 类型的指针实际上是一个指向 B 的指针。C 语言中有一个特殊的指针 void \* — 无类型指针。无类型指针可以指向任何数据,如果我们用它用作函数的参数和返回值,那么这个参数或返回值就可以是任何类型的指针,这也为构造泛型函数提供原料。
**例:泛型交换函数 (Generic Swap Function)**
```c
#include
void swap(void *vp1, void *vp2, int size) {
char buffer[size];
memcpy(buffer, vp1, size);
memcpy(vp1, vp2, size);
memcpy(vp2, buffer, size);
}
// usage
int main(int argc, char **argv) {
int a = 1;
int b = 2;
swap(&a, &b, sizeof(int));
double f1 = 0.5;
double f2 = 0.8;
swap(&f1, &f2, sizeof(double));
char *husband = strdup("Fred");
char *wife = strdup("Wilma");
swap(&husband, &wife, sizeof(char *)); // 注意这里,交换的是两个指针
}
```
本质上,不论是什么类型的数据,只要这些数据在内存当中是连续的,那么交换它们实际上就是交换两段连续的内存。只要知道两段内存的地址 (vp1, vp2),以及内存长度 (size),就可以使用 generic swap 来实现交换。最后一例中的字符串交换示意图见下图: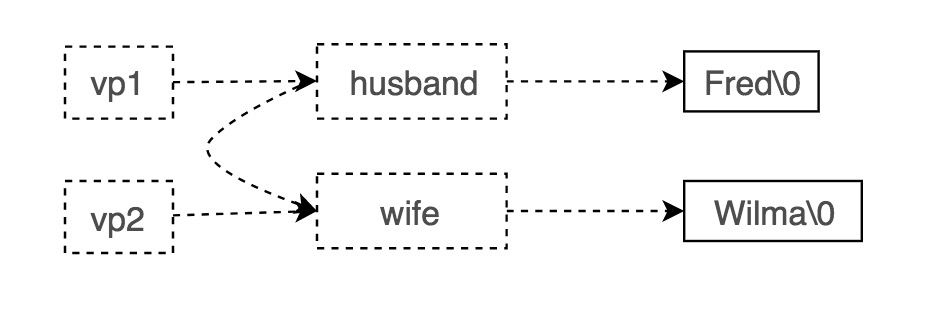
**例:泛型线性搜索 (Generic Linear Search)**
```c
void *lsearch(void *key, void *base, int size, int elemSize) {
for (int i = 0; i < size; i++) {
void *elemAddr = (char *)base + i * elemSize;
if (memcmp(key, elemAddr, elemSize) == 0) {
return elemAddr;
}
}
return NULL;
}
```
同理,不论是什么类型的数组,只要知道数组所在内存的地址 (base) 和查询目标内存的地址 (key),以及每个元素的长度 (elemSize) — 字节数,就可以拿着目标所在内存段与数组所在内存段进行一一比对,直到找到或者遍历数组结束为止。
更进一步,可以制定比较两个元素的方法
```c
void *lsearch(void *key, void *base,
int size, int elemSize,
int (*cmpfn)(void *, void *)) {
for (int i = 0; i < size; i++) {
void *elemAddr = (char *)base + i * elemSize;
if (cmpfn(key, elemAddr) == 0) return elemAddr;
}
return NULL;
}
```
**比较 int**
```c
int array[] = {4, 2, 3, 7, 11, 6};
int size = sizeof(array) / sizeof(int);
int number = 7;
int IntCmp (void *elem1, void *elem2) {
int *ip1 = elem1;
int *ip2 = elem2;
return *ip1 - *ip2;
}
int *found = lsearch(&number, array, size, sizeof(int), IntCmp);
```
**比较 string**
```c
char *notes[] = {"Ab", "F#", "B", "Gb", "D"};
char *favorateNote = "Gb";
int size = sizeof(notes) / sizeof(char *);
int StrCmp(void *vp1, void *vp2) {
char *s1 = *(char **)vp1;
char *s2 = *(char **)vp2;
return strcmp(s1, s2);
}
char **found = lsearch(&favorateNode, notes, size, sizeof(char *), StrCmp);
```
#### 小结:
本课内容让我联想到软件开发的基本定律 (Fundamental theorem of software engineering):
> All problems in computer science can be solved by another level of indirection
#### 参考
* [Stanford CS107: lecture 4](https://www.youtube.com/watch?v=_eR4rxnM7Lc\&index=4\&list=PL9D558D49CA734A02)
* [Stanford CS107: lecture 5](https://www.youtube.com/watch?v=73Z7gaAvovQ\&list=PL9D558D49CA734A02\&index=5)
* [Github: ZhengHe-MD - lecture codes](https://github.com/ZhengHe-MD/cs107-lecture-codes)